Paper Review - Embers of Autoregression
Example: ROT-13 vs ROT-2
Consider a “ROT-2” cipher task for ChatGPT and its deciphered text (using the ROT cipher decoder tool):
Create a cipher text by shifting each letter 2 positions backward for this text:
Hello world the p doom is high.
Fcjjm ykncb rfc n bllk gkm fq fgjf <-- ChatGPT output
Hello amped the p dnnm imo hs hilh <-- Deciphered text. Compare with input prompt.The cipher is way off except for the first word. Even the character counts don’t match!
The Embers of Autoregression
As we think of delegating judgment to Generative AI systems, in the paper, “Embers of Autoregression: Understanding Large Language Models Through the Problem They are Trained to Solve”, McCoy et al. caution about the embers of LLMs, especially in what they call low-probability situations [1].

They say:
- AI practitioners should be careful about using LLMs in low-probability situations.
- We should not evaluate LLMs as if they are humans but should instead treat them as a distinct type of system — one that has been shaped by its own particular set of pressures.
- LLMs will perform better on tasks that are frequently illustrated in Internet text than on tasks that occur more rarely — even when the rare task is no more complex than the common one.
Some low-probability Situations
A few such low-probability situations where LLM performance drops drastically for GPT-3.5 and GPT-4:
- Keyboard cipher task - a cipher where each letter is replaced with the letter to the right of it on a QWERTY keyboard. If the letter does not have a letter to its right, then you should wrap around to the start of the row
- ROT-2 task compared to ROT-13, a task which is 60 times more popular in internet texts - create a cipher text by shifting each letter 2 positions backward for this text
- Sort reverse alphabetical vs. sort alphabetical
- Birthday of a more popular celebrity than a less famous on - Birthday of Carrie Underwood vs. Jacques Hanegraaf
Such low-probability situations for either the tasks, inputs or outputs drastically affect performance.
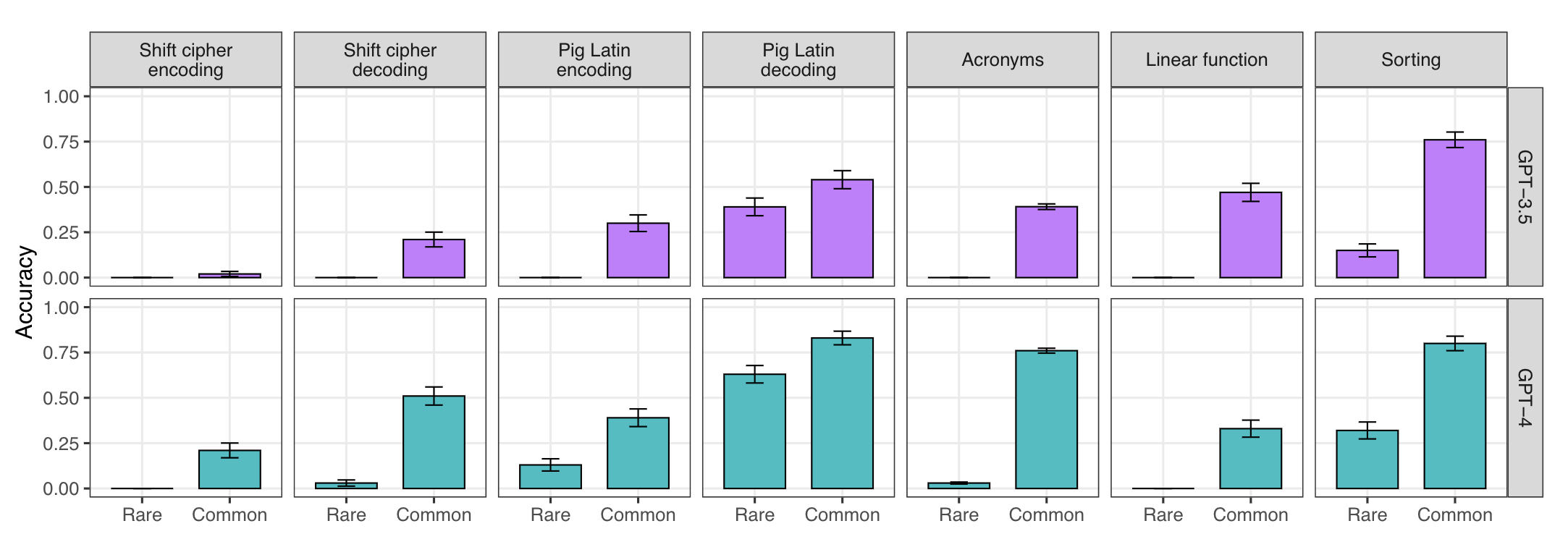
This challenge is related to the classic generalization problem in machine learning. A practitioner must be aware of these shortcomings when placing trust in LLM outputs.
Questions to Ask
A responsible AI practitioner must ask:
- Is my task a low-probability task, i.e. the LLM might have not seen it in the training corpus?
- Even if a task is seen, do I assume the LLM will perform well on a similar task? Do I have empirical data to show that it does perform equally well?
- Are my inputs or outputs low-probability sequences?
- How do I evaluate my implementation, especially for a low-probability tasks?
- Am I relying on over-generalization when I shouldn’t?
- How often might these low-probability situations arise in my system? What will be their impact?
References
[1] R. T. McCoy, S. Yao, D. Friedman, M. Hardy, and T. L. Griffiths, “Embers of Autoregression: Understanding Large Language Models Through the Problem They are Trained to Solve.” arXiv, Sep. 24, 2023. doi: 10.48550/arXiv.2309.13638. Available: http://arxiv.org/abs/2309.13638. [Accessed: Jun. 29, 2024] ↩︎